
刚刚,谷歌DeepMind发布了Gemma 4 12B。
一句话概括这个模型的定位:把原本需要高端服务器才能跑的多模态智能,装进你的笔记本电脑里。
它填补的是Gemma家族里一个关键空缺:比边缘端的E4B更强,比26B混合专家模型(MoE)更轻。而且在整个Gemma 4系列里,它是第一个支持原生音频输入的中等规模模型。
到底有多能打?
先说跑分。Gemma 4 12B在标准评测基准上的成绩接近26B MoE模型,但总内存占用还不到后者的一半。
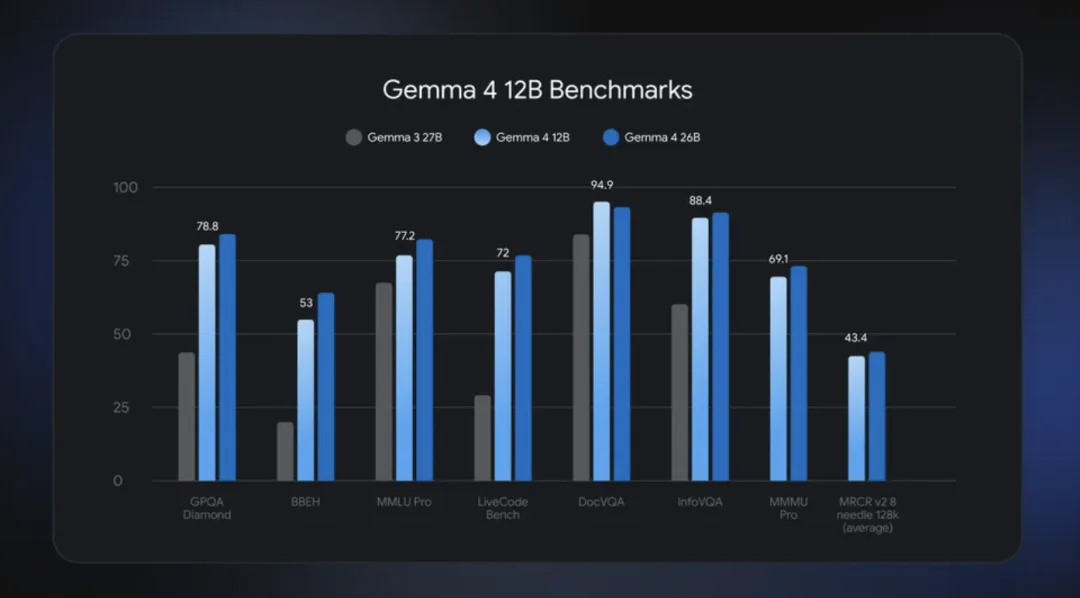
硬件门槛方面:只需要16GB显存或统一内存,消费级笔记本电脑就能运行,也就是入门级的MacBook Air(M5) 就能跑了
能力方面,它支持强大的多步推理和智能体工作流。多模态理解加上Agent能力,直接在本地跑,不用联网,不依赖云端。
本地体验入口有:LM Studio、Ollama、Google AI Edge Gallery App、Google AI Edge Eloquent应用(可以直接看到完全离线的语音转录、格式化和翻译效果)、LiteRT-LM CLI。
我已经第一时间通过LM Studio安装了,以后就算断网,本地也有真正的多模态模型了,没有任何token焦虑,不过最好上32g内存,16g虽然可以跑,但是token速度很慢,另外中文表达默认好像是粤语表达方式,所以问问题之前要求用简体中文来回答,知识截止日期2025年1月。
最核心的技术创新:扔掉编码器
这是Gemma 4 12B最值得说的地方。
传统的多模态模型,处理图片或音频的方式是这样的:先用专门的编码器把图像、音频"翻译"成模型能懂的表示,再把这些表示传给语言模型主体。编码器越多,延迟越高,内存占用也越大。
谷歌这次直接把编码器去掉了。
视觉处理方面,他们用一个极轻量的嵌入模块替换了原来的视觉编码器,这个模块只包含一次矩阵乘法、位置嵌入和归一化操作。视觉信息就这样直接进入语言模型主干,让大模型自己去做视觉理解。
音频处理方面,走得更彻底。音频编码器被完全移除,原始音频信号直接被投影到与文本token相同的维度空间里。
这种统一、无编码器的架构,带来的直接好处是:延迟更低,内存更省。
还有一个细节:速度优化
Gemma 4 12B内置了多Token预测(MTP)草稿器,专门用来降低推理延迟。这个技术我之前的文章有介绍过,目前谷歌已经用到自家全系模型了
这在实际使用中意味着响应更快。
Apache 2.0,完全开放
许可证方面,Gemma 4 12B采用Apache 2.0协议发布,开发者可以自由使用。
预训练权重和指令微调权重都可以直接从Hugging Face和Kaggle下载。
支持的推理框架包括:Hugging Face Transformers、llama.cpp、MLX、SGLang、vLLM。微调方面支持Unsloth。
生产部署方面,支持通过谷歌云上线,可以走Gemini企业级智能体平台模型花园、Cloud Run和GKE。
配套生态同步上线
谷歌这次还一并发布了官方Gemma技能库(Skills Repository),专门为开发者用Gemma模型构建智能体工作流提供支持,里面的技能库是专门为Gemma设计的。
开发者文档和快速入门Notebook也同步上线。
开发者指南:
https://developers.googleblog.com/gemma-4-12b-the-developer-guide/
权重:
https://huggingface.co/collections/google/gemma-4
参考:
https://blog.google/innovation-and-ai/technology/developers-tools/introducing-gemma-4-12B/










用户评论