感觉大家对追新这事,没那么上头了。
要是去年,哪怕是大半夜发个新模型,朋友圈里必定有一票人熬夜实测。现在甩个新闻链接大家点个赞就算看过了。
我复盘了下大家热情消退的最大原因,就是现有模型已经够强了。
以前是我们拿既有问题去试,测完都觉得差口气。现在随便拎个主流模型出来,给 Agent 一挂,稳如老狗,自然懒得再去折腾所谓的“参数突破”。
当我们的关注点从模型有多聪明,变成 Agent 一天到底能出多少活的时候,你就会发现它干活,绝不是一问一答那么简单。
它需要不断地规划、调用工具、验证和纠错。这就导致它要处理的上下文长度,通常是普通对话的成百上千倍。只要任务还在推进,信息就会层层累加,Token 消耗量直接爆炸,响应速度也开始肉眼可见地变慢。

前几天,CMU、Yale 等顶级机构联合发布了一篇 71 页的综述论文,专门探讨了一个概念:Agent Harness Engineering(智能体驾驭工程)。
这篇论文印证了我长久以来的想法:大模型 Agent 的可靠性不能只盯着模型本身。
最开始我们拼命钻研 Prompt,后来折腾 Context,把能塞的记忆全塞进去。即使是精心调优的 Agent,或许能完美处理 95% 的任务,但在剩下的 5% 里,它可能会编造一个不存在的 API,或者在执行跨平台比对时陷入死循环。

在生产环境里,这 5% 的不确定性是灾难性的。
基础设施领域的传奇人物 Mitchell Hashimoto 提出了一个公式:Agent = Model + Harness。
打个比方,现在的顶级大模型就像一台马力过万匹的顶级发动机,它的动力很强,但如果你把它直接焊在普通自行车的车架上,一踩油门,四分五裂。
Harness(驾驭系统)做的不是提升发动机的马力,而是整车的传动轴、变速箱、刹车片和冷却水箱,都限制在安全的区间内。
前不久在 Create 2026 百度AI开发者大会上,百度智能云事业群总裁沈抖在《万物一体,AI云为基》主题演讲中就聊透了这个趋势,他抛出了一个让我印象极深的行业断言:“AI 云的下半场,不是比谁消耗了更多的 Token,而是比谁能用好每一个 Token。”

如果 Agent Infra 不给力,Token 纯粹是被无效的“死循环”和“幻觉”白白浪费掉的。未来的企业,不再会问“你用了哪个模型”,只会问“你的智能体一天干了多少有价值的活”。
想要让企业“多、快、好、省”地把 Token 转化为实打实的生产力,就必须依靠一套完善的智能体基础设施。而百度千帆最近的一系列大动作,正是把这套逻辑落到了最底层的系统重构上。
他们祭出的第一招,就是直接对 Token 的“生产模式”动刀。

百度千帆 Agent Infra
百度千帆的第一层支撑,叫 Token Factory(词元工厂)。
百度这次是把过去的 MaaS 模型服务,彻底升级成了一个面向智能体时代的 Token 生产系统。
以前我们用大模型,平台更像是个“模型超市”,我们进去挑个模型挂上就完事了。但智能体时代不行,Agent 的多轮规划、工具调用,导致它要处理的上下文直接飙升到对话的成百上千倍。这时候还玩手工作坊式的模型调用,成本和速度根本扛不住。
所以,词元工厂做的是一次工业化的重构。它用 Agent-First 的逻辑,在底层尽可能剔除掉重复计算的 Token。体现在具体业务上,推理速度快了 25%,首 Token 的弹出时间缩短了 16%。
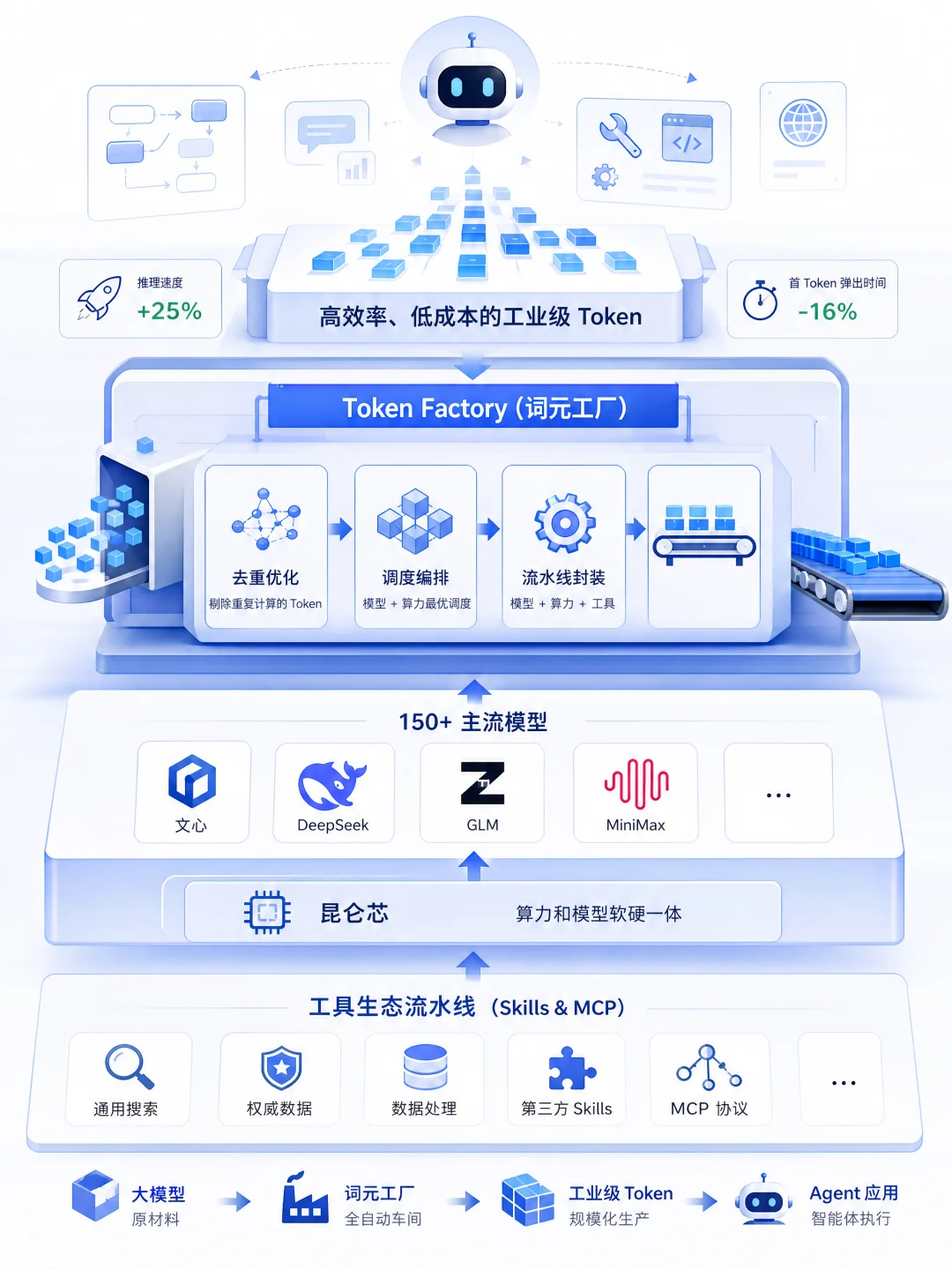
这里面容纳了 150 个主流模型,如文心,DeepSeek、GLM、MiniMax 这些大家常用的旗舰模型,底层跑的是国产昆仑芯,算力和模型软硬一体。
更重要的是,它把工具生态也做成了流水线,内置了百度自有的和第三方的 Skills 与 MCP(通用搜索、权威数据、数据处理等)。你可以理解为,大模型现在只是“原材料”,而词元工厂是一个全自动车间,把模型、算力、工具打包在一起,变成高效率、低成本的工业级 Token,源源不断地供给你的 Agent。
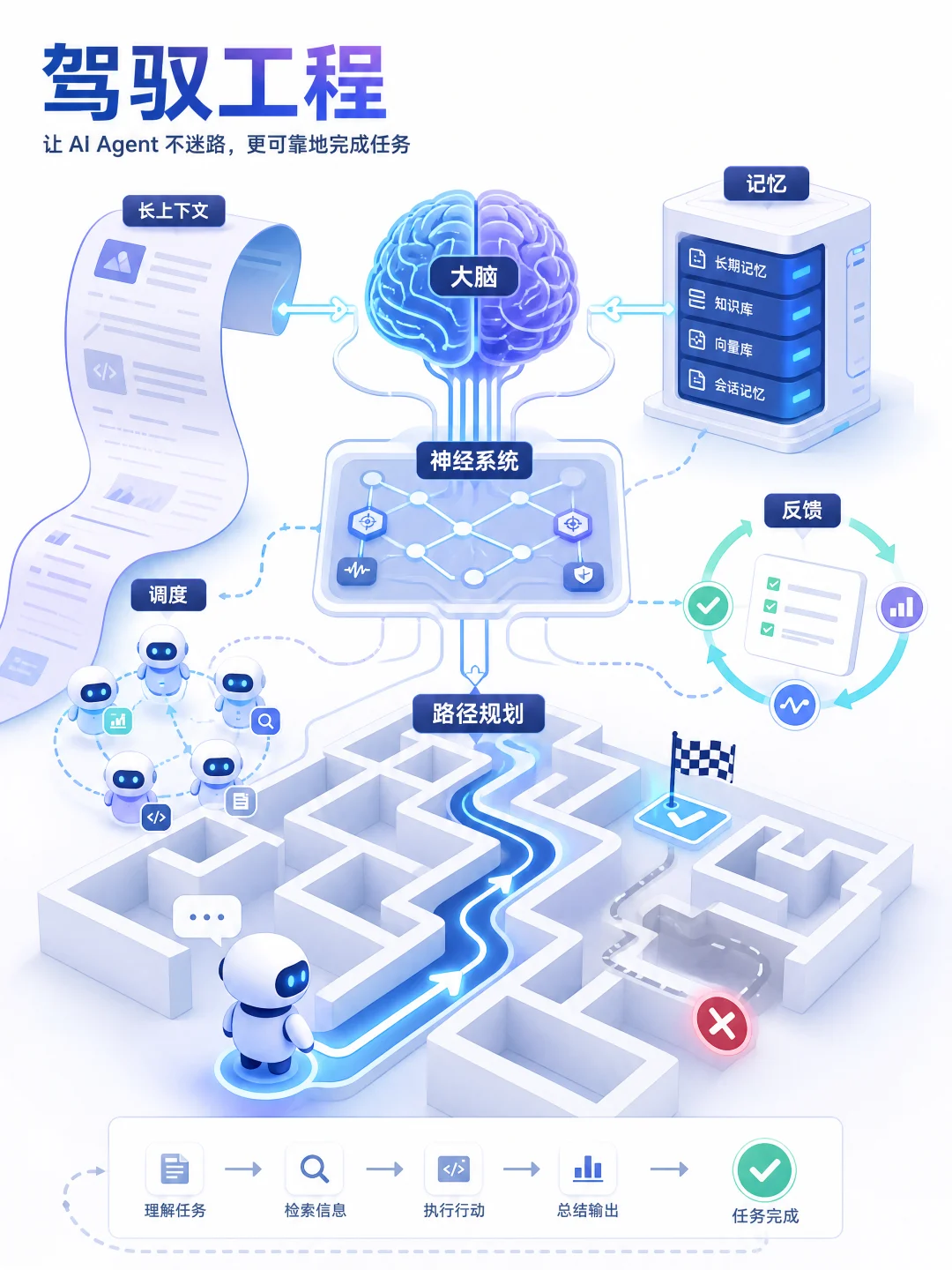
再看“驾驭工程”。如果在座有开发者,大概都吃过“智能体绕弯路”的苦。
让 Agent 去处理一个多步骤的办公任务,它有时候会像个无头苍蝇,在一个死胡同里来回调用工具,白白烧掉大量 Token。
驾驭工程解决的就是这个路径规划问题。它把长上下文管理、持久记忆、子智能体调度和评估反馈整合在一起。
模型是大脑,Harness Engineering(驾驭工程)就是神经系统,解决的是智能体执行任务时的路径规划与边界问题。
现在百度千帆的驾驭工程,把长上下文管理、持久记忆、子智能体调度和评估反馈深度整合在了一起。
分享一个我自己的实际业务案例:
上周我需要处理一批跨平台的数据比对任务。要求 Agent 先去指定的几个外网抓取同类产品的价格历史,再去本地指定的几个 Excel 表格里提取对应时段的销售基数,最后交叉比对输出一份定价建议。
以前用普通的框架跑,中间常常因为表格格式或者网页结构稍微变化,Agent 就开始陷入死循环的尝试中。这次在百度千帆的驾驭工程下,同样的一套逻辑流,它会在遇到数据报错时,调用记忆库里的历史纠错记录,自动修正搜索关键词。
一趟跑下来,它需要的对话轮次明显变少。由于上下文管理上的优化,对比我之前用 OpenClaw 跑类似的流程,Token 消耗直接降了 23%。在浏览器、Office 这类常规办公场景里,任务执行成功率可以维持在 95% 左右。
在这个闭环里,模型和 Harness 越好用,搭出的智能体就越顺手;智能体在执行任务中沉淀下来的技能和反馈数据,又会流转回词元工厂,继续推动整个系统进化。
只要是在百度千帆 Agent 里搭建的智能体,都是在 Agent Infra 这套基础设施上开发出来的。这是一套能支持智能体协同进化的基础设施。
此外我还看了下百度千帆的 Token 福利包,这性价比绝对可以给到一个夯了。有需要的小伙伴抓紧入手~

百度千帆官网:
https://cloud.baidu.com/product/qianfan_home/token.html
这是一个统一的 AI 额度池。它把大模型调用和 Skills 工具使用,都折算成了统一的积分。
DeepSeek、Kimi、GLM-5.1、MiniMax、ERNIE 都在额度池里,根据任务轻重随时切换。
还能直接调用搜索、文档处理等百度原生 Skills。

并全端兼容手机虾、桌面虾、网页虾,也能直接接入 Claude Code、Codex 等十几种主流AI编程辅助工具。

写在最后
模型不运行系统,是系统运行模型。
不是换个更强的模型就能解决业务问题了。今天大部分旗舰模型智商已经溢出了,决定你的 Agent 是个“玩具”还是“生产力工具”的,恰恰是模型外面的 Agent Infra。
人类历史上,用火、建炉子,用蒸汽机、发明电网,底层逻辑都是一致的。先找到一股强大的力量,然后建一套系统,把它安全、持续、可复制地引导到我们需要的地方。
现在的竞争已经跨越了“模型参数”阶段,进入了“单位 Token 生产力”的较量。所以未来的工作流里,大家只会看你的智能体交付了多少正确结果。










用户评论